后进者先出,先进者后出,这就是典型的“栈”结构。
从栈的操作特性上来看,栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,我们就应该首选“栈”这种数据结构。
实现一个“栈”
栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。以下代码是一个基于数组来实现的顺序栈。
|
|
不管是顺序栈还是链式栈,我们存储数据只需要一个大小为 n 的数组就够了。在入栈和出栈过程中,只需要一两个临时变量存储空间,所以空间复杂度是 O(1)。我们说空间复杂度的时候,是指除了原本的数据存储空间外,算法运行还需要额外的存储空间。
动态扩容的顺序栈
要实现一个支持动态扩容的栈,只需要底层依赖一个支持动态扩容的数组就可以了。当栈满了之后,我们就申请一个更大的数组,将原来的数据搬移到新数组中。
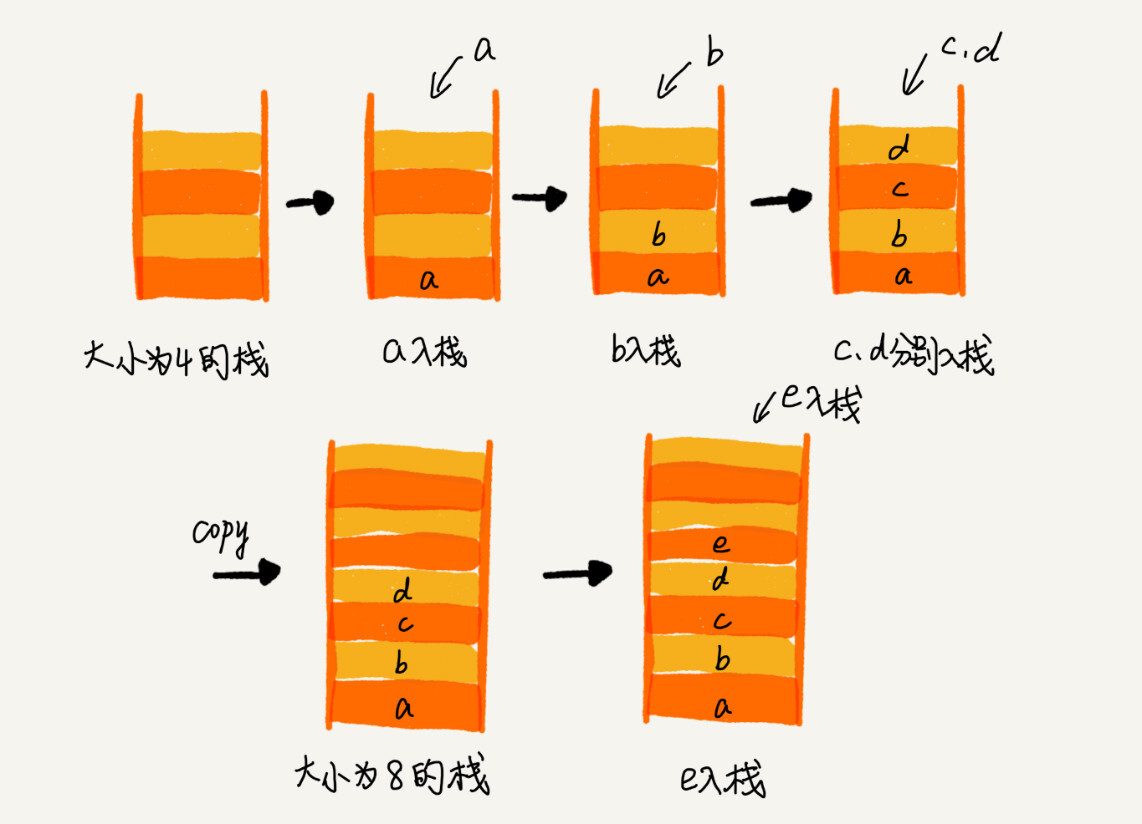
对于出栈操作来说,由于不会涉及内存的重新申请和数据的搬移,所以出栈的时间复杂度仍然是 O(1)。对于入栈操作来说,当栈中有空闲空间时,入栈操作的时间复杂度为 O(1)。但当空间不够时,就需要重新申请内存和数据搬移,所以时间复杂度就变成了 O(n)。对于平均时间复杂度,我们可以用摊还分析法来分析。
我们先做一些假设和定义:
- 栈空间不够时,我们重新申请一个是原来大小两倍的数组;
- 为了简化分析,假设只有入栈操作没有出栈操作;
- 定义不涉及内存搬移的入栈操作为 simple-push 操作,时间复杂度为 O(1)。
如果当前栈大小为 K,并且已满,当再有新的数据要入栈时,就需要重新申请 2 倍大小的内存,并且做 K 个数据的搬移操作,然后再入栈。但是,接下来的 K-1 次入栈操作,我们都不需要再重新申请内存和搬移数据,所以这 K-1 次入栈操作都只需要一个 simple-push 操作就可以完成。
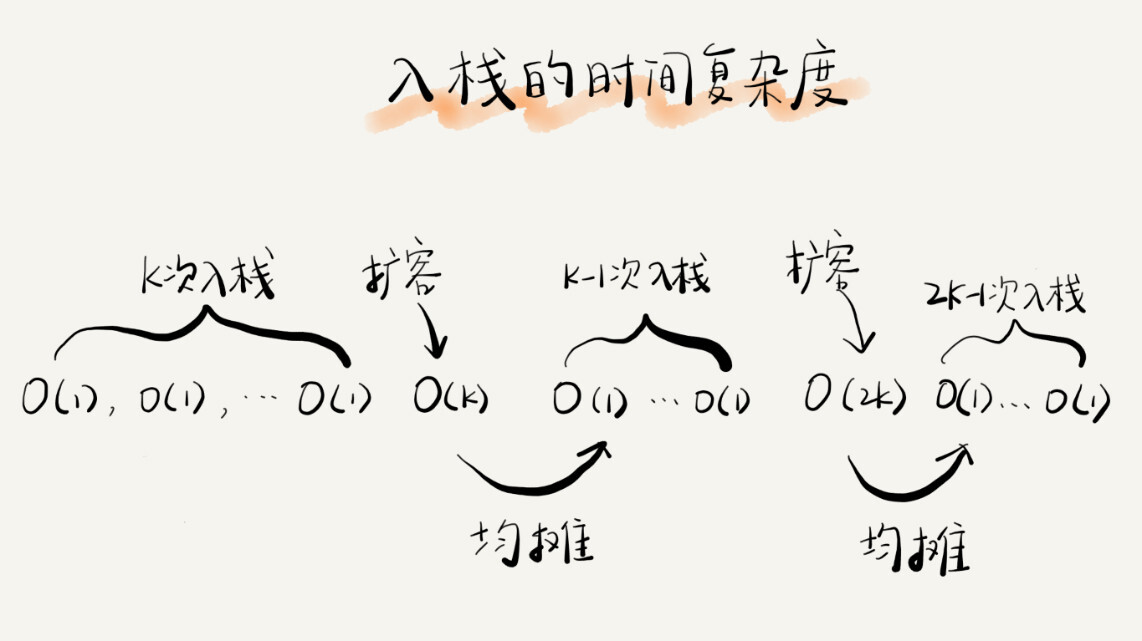
这 K 次入栈操作,总共涉及了 K 个数据的搬移,以及 K 次 simple-push 操作。将 K 个数据搬移均摊到 K 次入栈操作,那每个入栈操作只需要一个数据搬移和一个 simple-push 操作。以此类推,入栈操作的均摊时间复杂度就为 O(1)。
这也印证了前面讲到的,均摊时间复杂度一般都等于最好情况时间复杂度。因为在大部分情况下,入栈操作的时间复杂度 O 都是 O(1),只有在个别时刻才会退化为 O(n),所以把耗时多的入栈操作的时间均摊到其他入栈操作上,平均情况下的耗时就接近 O(1)。
栈在函数调用中的应用
栈的一个经典应用场景就是函数调用栈。
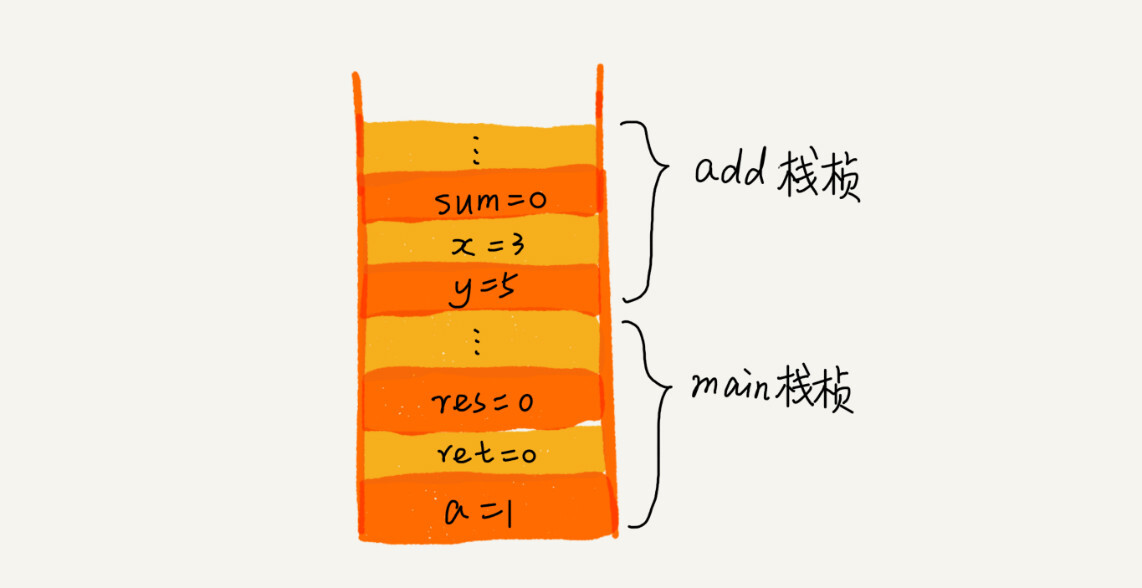
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
|
|
上面代码中,main() 函数调用了 add() 函数,获取计算结果,当执行到add() 函数时,其函数调用栈情况如下图:
栈在表达式求值中的应用
编译器利用栈来实现表达式求值就是栈的另一个常见的应用场景。
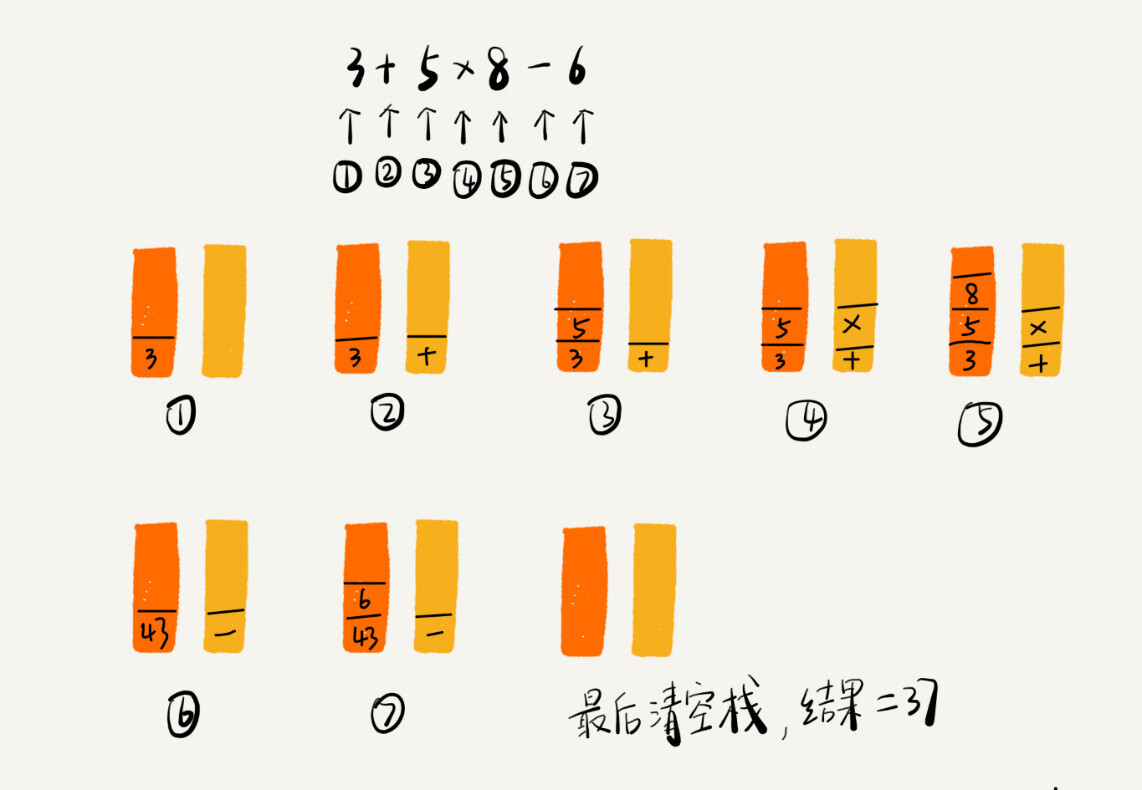
编译器就是通过两个栈来实现的。其中一个保存操作数的栈,另一个是保存运算符的栈。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。
如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。
例如3+5*8-6 这个表达式的计算过程如下图所示:
栈在括号匹配中的应用
我们还可以借助栈来检查表达式中的括号是否匹配。
假设表达式中只包含三种括号,圆括号 ()、方括号 [] 和花括号{},并且它们可以任意嵌套。比如,{[{}]}或 [{()}([])] 等都为合法格式,而{[}()] 或 [({)] 为不合法的格式。这时候就可以借助栈来检验他们的合法性。
我们用栈来保存未匹配的左括号,从左到右依次扫描字符串。当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号。如果能够匹配,比如“(”跟“)”匹配,“[”跟“]”匹配,“{”跟“}”匹配,则继续扫描剩下的字符串。如果扫描的过程中,遇到不能配对的右括号,或者栈中没有数据,则说明为非法格式。
当所有的括号都扫描完成之后,如果栈为空,则说明字符串为合法格式;否则,说明有未匹配的左括号,为非法格式。
栈在浏览器中的应用
实现浏览器的前进、后退功能其实用两个栈就可以完美实现。
我们使用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了。
比如你顺序查看了 a,b,c 三个页面,我们就依次把 a,b,c 压入栈,这个时候,两个栈的数据就是这个样子:
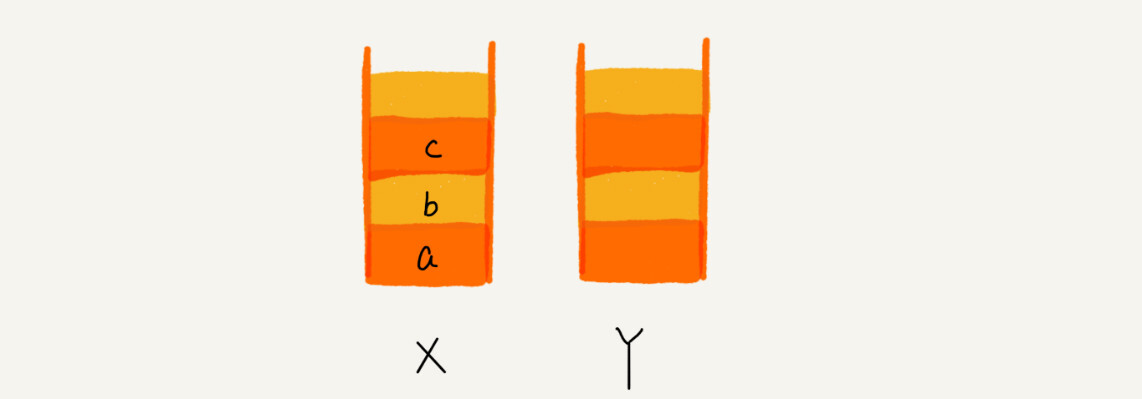
当你通过浏览器的后退按钮,从页面 c 后退到页面 a 之后,我们就依次把 c 和 b 从栈 X 中弹出,并且依次放入到栈 Y。这个时候,两个栈的数据就是这个样子:
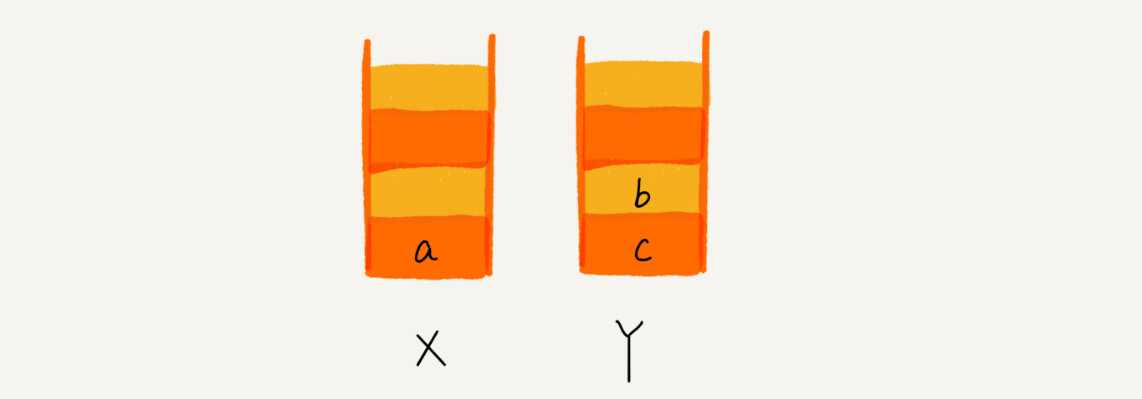
这个时候你又想看页面 b,于是你又点击前进按钮回到 b 页面,我们就把 b 再从栈 Y 中出栈,放入栈 X 中。此时两个栈的数据是这个样子:
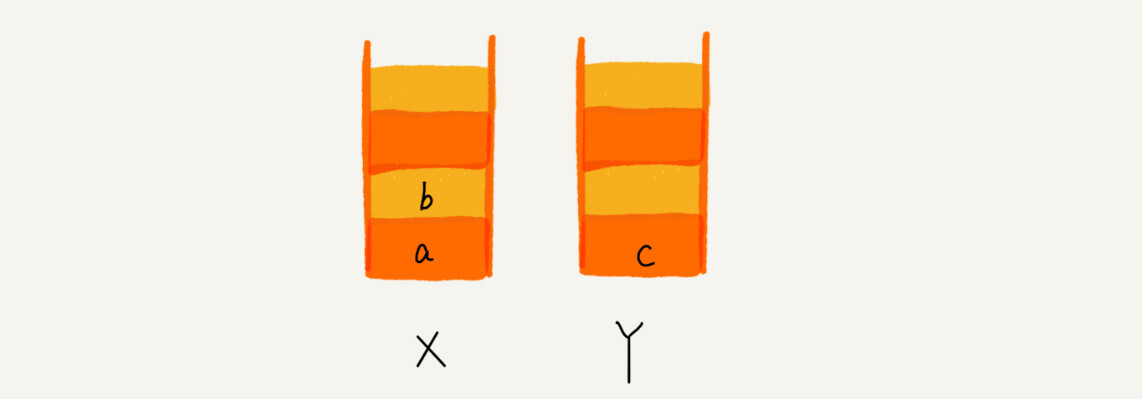
这个时候,你通过页面 b 又跳转到新的页面 d 了,页面 c 就无法再通过前进、后退按钮重复查看了,所以需要清空栈 Y。此时两个栈的数据这个样子:
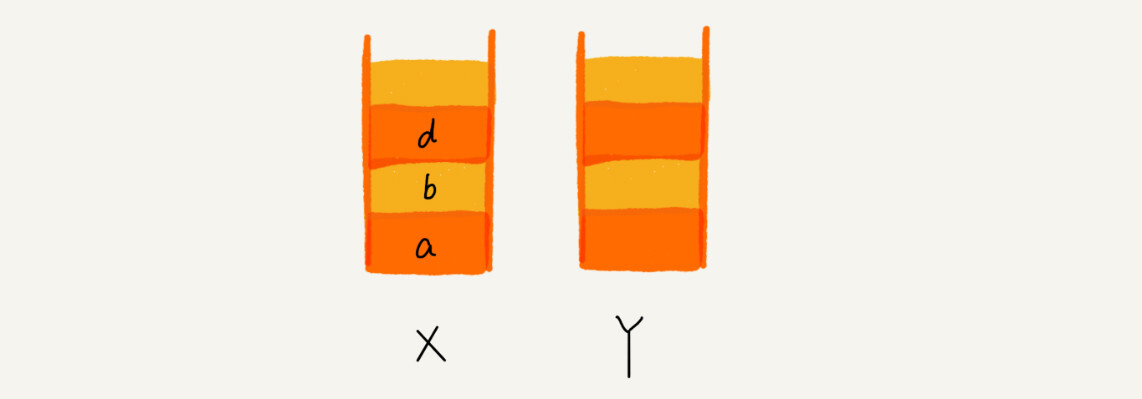
内容小结
栈是一种操作受限的数据结构,只支持入栈和出栈操作。后进先出是它最大的特点。栈既可以通过数组实现,也可以通过链表来实现。不管基于数组还是链表,入栈、出栈的时间复杂度都为 O(1)。